TensorFlow 的 TFRecord 和 QueueRunner 简介
通常我们下载的数据集都是以压缩文件的格式存在,解压后会有多个文件夹,像 train, test, val 等等。而文件也有可能多达数万或者数百万个。这种形式的数据集不但读取复杂、慢,而且占用磁盘空间。这时二进制的格式文件的优点便显现出来了。我们可以把数据集存储为一个二进制文件,这样就没有了 train, test, val 等等的文件夹。更重要的是,这些数据只会占据一块内存(Block of Memory),而不需要一个一个单独加载文件。因此使用二进制文件效率更高。
你以为 TensorFlow 都为你封装好二进制文件文件的读写、解析方式了吗?是的,都封装好了~本文就是介绍如何将数据转换为 TFRecord 格式。
CIFAR-10 数据集
本文以 CIFAR-10 数据集为例,什么是 CIFAR-10 数据集?看这儿 => 图像数据集 ~
假设你已经有了以下数据:
写,保存为 TFRecord 格式
定义的一些常量:
_NUM_TRAIN_FILES = 5
# The height and width of each image.
_IMAGE_SIZE = 32
# The names of the classes.
_CLASS_NAMES = [
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck',
]
这里我们创建两个 split 文件,分别存储 train 和 test 需要的数据:
dataset_dir = 'data'
if not tf.gfile.Exists(dataset_dir):
tf.gfile.MakeDirs(dataset_dir)
training_filename = _get_output_filename(dataset_dir, 'train')
testing_filename = _get_output_filename(dataset_dir, 'test')
_get_output_filename 函数用来生成文件名:
def _get_output_filename(dataset_dir, split_name):
"""Creates the output filename.
Args:
dataset_dir: The dataset directory where the dataset is stored.
split_name: The name of the train/test split.
Returns:
An absolute file path.
"""
return '%s/cifar10_%s.tfrecord' % (dataset_dir, split_name)
然后,处理训练数据:
# First, process the training data:
with tf.python_io.TFRecordWriter(training_filename) as tfrecord_writer:
offset = 0
for i in range(_NUM_TRAIN_FILES):
filename = os.path.join('./cifar-10-batches-py', 'data_batch_%d' % (i + 1))
offset = _add_to_tfrecord(filename, tfrecord_writer, offset)
即依次读取 data_batch_? 文件,调用 _add_to_tfrecord 将其保存为 TFRecord 格式。
def _add_to_tfrecord(filename, tfrecord_writer, offset=0):
"""Loads data from the cifar10 pickle files and writes files to a TFRecord.
Args:
filename: The filename of the cifar10 pickle file.
tfrecord_writer: The TFRecord writer to use for writing.
offset: An offset into the absolute number of images previously written.
Returns:
The new offset.
"""
with tf.gfile.Open(filename, 'rb') as f:
data = pickle.load(f, encoding='bytes')
images = data[b'data']
num_images = images.shape[0]
images = images.reshape((num_images, 3, 32, 32))
labels = data[b'labels']
with tf.Graph().as_default():
image_placeholder = tf.placeholder(tf.uint8)
encoded_image = tf.image.encode_png(image_placeholder)
with tf.Session() as sess:
for j in range(num_images):
sys.stdout.write('\r>> Reading file [%s] image %d/%d' % (filename, offset + j + 1, offset + num_images))
sys.stdout.flush()
image = np.squeeze(images[j]).transpose((1, 2, 0))
label = labels[j]
png_string = sess.run(encoded_image, feed_dict={image_placeholder: image})
example = image_to_tfexample(png_string, b'png', _IMAGE_SIZE, _IMAGE_SIZE, label)
tfrecord_writer.write(example.SerializeToString())
return offset + num_images
因为 CIFAR-10 数据集的图片是 10000x3072 numpy array 格式的,因此需要 reshape 为 tf.image.encode_png 需要的格式:[height, width, channels]。 tf.image.encode_png 返回编码后的字符串,然后还需要保存图片的宽高、格式信息。调用 image_to_tfexample 将这些数据保存到 tf.train.Example 中:
def image_to_tfexample(image_data, image_format, height, width, class_id):
return tf.train.Example(features=tf.train.Features(feature={
'image/encoded': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_data])),
'image/format': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_format])),
'image/class/label': tf.train.Feature(int64_list=tf.train.Int64List(value=[class_id])),
'image/height': tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
'image/width': tf.train.Feature(int64_list=tf.train.Int64List(value=[width])),
}))
TensorFlow 会将数据转换为 tf.train.Example Protobuf 对象,Example 包含 Features, Features 包含 一个 dict,来区分不同的 Feature。Feature 可以包含 FloatList,ByteList 或者 Int64List。注意这里的 key,image/encoded,image/format等,是可以随便定义的,这里是TensorFlow 默认的图片数据集的 key ,我们一般采取 TensorFlow 默认的值。
有了 example,我们将其转换为字符串写入到文件就完成了整个 TFRecord 格式文件的制作。
tfrecord_writer.write(example.SerializeToString())
同理,制作测试数据集:
# Next, process the testing data:
with tf.python_io.TFRecordWriter(testing_filename) as tfrecord_writer:
filename = os.path.join('./cifar-10-batches-py', 'test_batch')
_add_to_tfrecord(filename, tfrecord_writer)
最后,我们会得到两个文件:

这就是最后的 TFRecord 格式文件,二进制文件。
读
最简单的就是直接读取:
reconstructed_images = []
record_iterator = tf.python_io.tf_record_iterator(path='./data/cifar10_train.tfrecord')
for string_iterator in record_iterator:
example = tf.train.Example()
example.ParseFromString(string_iterator)
height = example.features.feature['image/height'].int64_list.value[0]
width = example.features.feature['image/width'].int64_list.value[0]
png_string = example.features.feature['image/encoded'].bytes_list.value[0]
label = example.features.feature['image/class/label'].int64_list.value[0]
with tf.Session() as sess:
image_placeholder = tf.placeholder(dtype=tf.string)
decoded_img = tf.image.decode_png(image_placeholder, channels=3)
reconstructed_img = sess.run(decoded_img, feed_dict={image_placeholder: png_string})
reconstructed_images.append((reconstructed_img, label))
其实就是“写”的逆过程。生成一个 Example,分析读取的字符串,然后从 features 中根据 key 获取相应的对象即可。图片的话我们使用 tf.image.decode_png 解码,即 tf.image.encode_png 逆过程。
读取后可以直接来显示:
plt.imshow(reconstructed_images[0][0])
plt.title(_CLASS_NAMES[reconstructed_images[0][1]])
plt.show()
这种方法比较直接,直接从文件读取并分析,但是如果数据较多就会你比较慢,而且没有考虑分布式、队列、多线程的问题。我们还可以使用文件队列来读取。
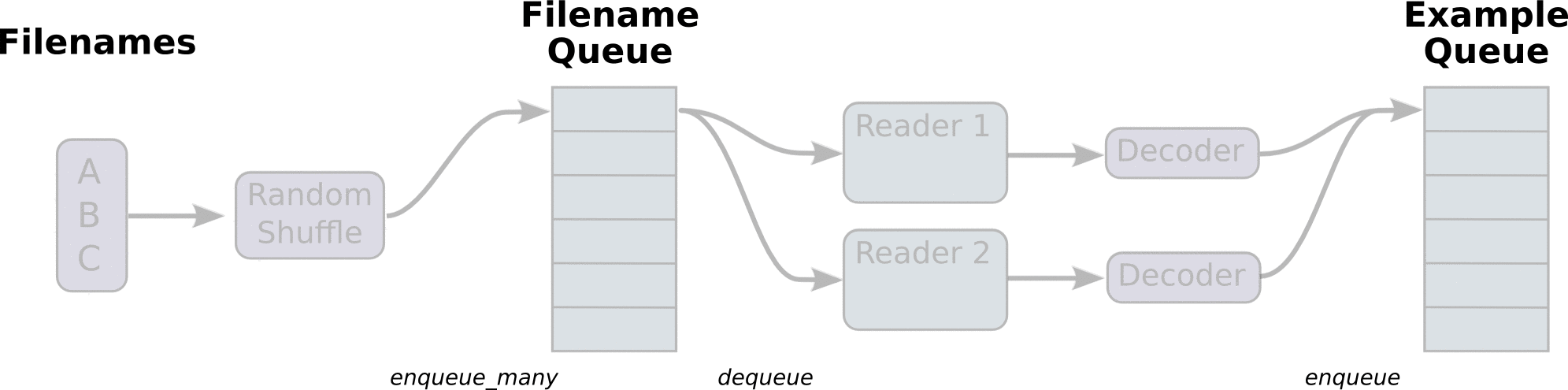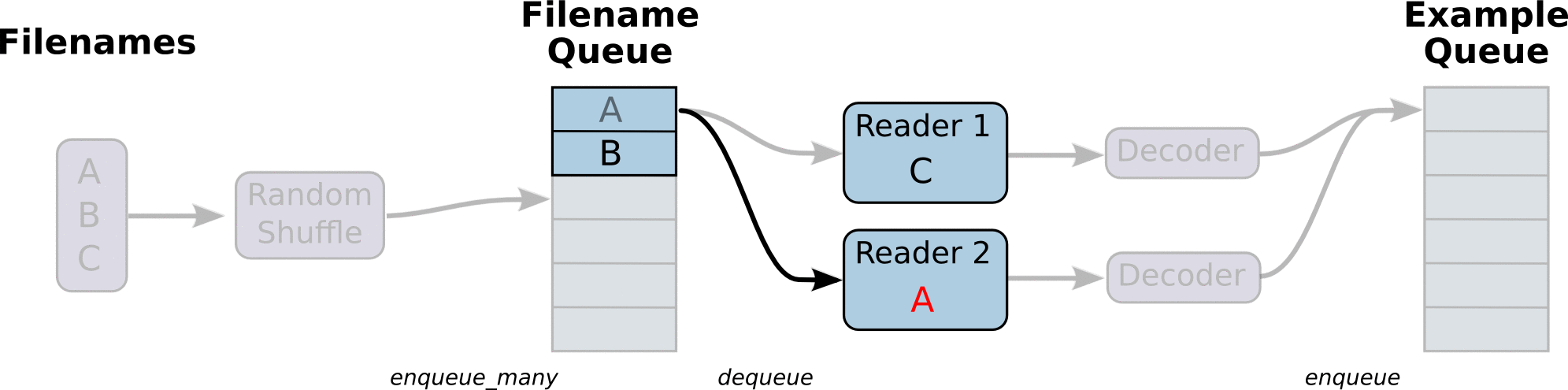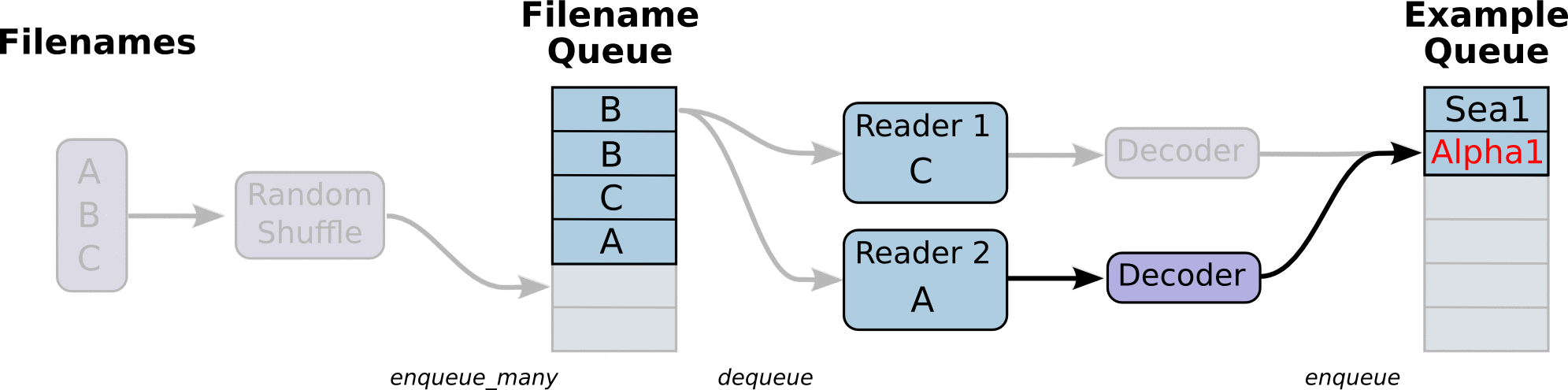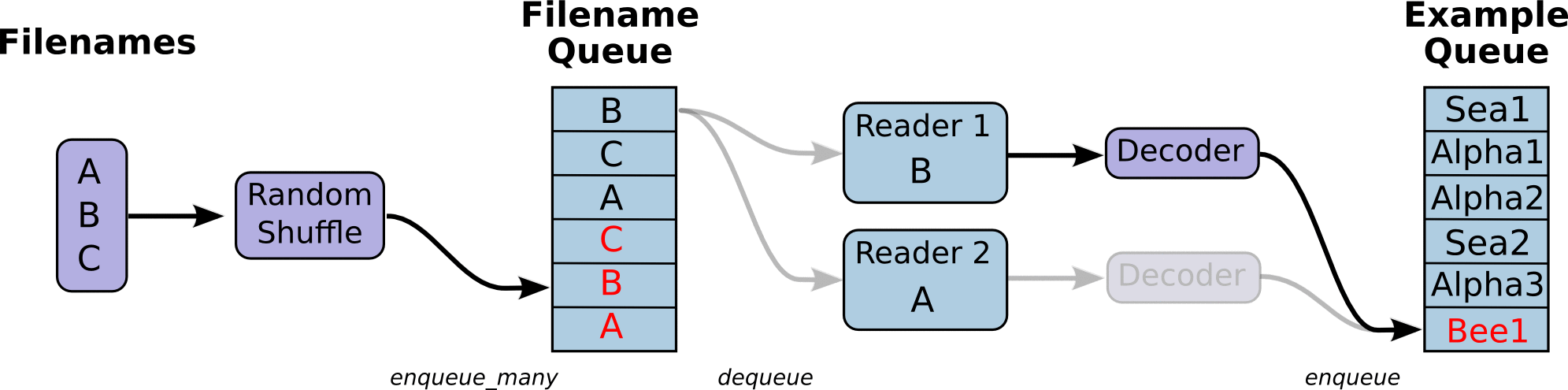
队列
# first construct a queue containing a list of filenames.
# this lets a user split up there dataset in multiple files to keep
# size down
filename_queue = tf.train.string_input_producer(['./data/cifar10_train.tfrecord'])
# Unlike the TFRecordWriter, the TFRecordReader is symbolic, 即所做的操作不会立即执行
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example, features={
'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
'image/format': tf.FixedLenFeature((), tf.string, default_value='png'),
'image/height': tf.FixedLenFeature((), tf.int64),
'image/width': tf.FixedLenFeature((), tf.int64),
'image/class/label': tf.FixedLenFeature([], tf.int64, default_value=tf.zeros([], dtype=tf.int64))
})
image = tf.image.decode_png(features['image/encoded'], channels=3)
image = tf.image.resize_image_with_crop_or_pad(image, 32, 32)
label = features['image/class/label']
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
with tf.Session() as sess:
sess.run(init_op)
tf.train.start_queue_runners()
# grab examples back.
# first example from file
image_val_1, label_val_1 = sess.run([image, label])
# second example from file
image_val_2, label_val_2 = sess.run([image, label])
print(image_val_1, label_val_1)
print(image_val_2, label_val_2)
plt.imshow(image_val_1)
plt.title(_CLASS_NAMES[label_val_1])
plt.show()
首先定义我们的文件名队列 filename_queue,包含一个文件名列表,这样我们可以把大的文件分成多个小的文件,保证单个文件不会太大,本例只有一个文件。然后用 TFRecordReader 读取。TensorFlow 的 graphs 包含一些状态变量,允许 TFRecordReader 记住 tfrecord 读到了哪儿,下次从哪儿读起,因此我们需要 sess.run(init_op) 来初始化这些状态。与 tf.python_io.tf_record_iterator 不同的是 TFRecordReader 总是作用在文件名(filename_queue)队列上,它会弹出一个文件名读取数据,直到 tfrecord 为空,然后读取下一个文件名对应的文件。
如何生成文件名队列呢,这时我们需要 QueueRunners 来做。QueueRunners 其实就是一个线程,使用 session 不断执行入队操作,TensorFlow 已经封装好了 tf.train.QueueRunner 对象。但是大部分时间 QueueRunner 只是底层操作,我们不会直接操作它,本例使用 tf.train.string_input_producer 生成。
此时,需要发送信号让 TensorFlow 开起线程,执行 QueueRunners,否则,代码将会永远阻塞,等待数据入队。因此需要执行 tf.train.start_queue_runners(),此行代码执行完会立即创建线程。注意,必须在 initialization 运算符(sess.run(init_op))执行之后调用。
tf.parse_single_example 根据我们定义的 features 数据格式解析。最终,image_val_1 就是图片数据集中的一张图片,shape 为 ( 32, 32, 3)。
队列读取的流程图如下:
Batch
上例中,我们获得的 image 和 label 都是单个的 Example 对象,代表数据集中的一条数据。训练的时候不可能单条数据训练,如何生成 batches?
images_batch, labels_batch = tf.train.shuffle_batch(
[image, label], batch_size=128,
capacity=2000,
min_after_dequeue=1000)
with tf.Session() as sess:
sess.run(init_op)
tf.train.start_queue_runners()
labels, images = sess.run([labels_batch, images_batch])
print(labels.shape)
这里我们使用 tf.train.shuffle_batch 将单个的 image 和 label Example 对象生成 batches 。tf.train.shuffle_batch 实际上构建了另一种 QueueRunner,RandomShuffleQueue。RandomShuffleQueue 将单个的 image 和 label 累积成队列,直到包含 batch_size + min_after_dequeue 个。然后随机选择 batch_size 条数据返回,因此 shuffle_batch 的返回值实际上是 RandomShuffleQueue 执行 dequeue_many 的返回值。
如果 tensor 的形状为 [x, y, z],shuffle_batch 返回的对应的 tensor 形状为 [batch_size, x, y, z],本例 labels 和 images 形状分别为(128, ) 和 (128, 32, 32, 3)。
DatasetDataProvider
如果我们使用 tf.contrib.slim,我们可以将读取过程封装的更优雅。
定义我们的数据集 cifar10.py,具体怎么定义相信看了以上代码,下面的代码不用解释也能看懂了吧~
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tensorflow as tf
slim = tf.contrib.slim
_FILE_PATTERN = 'cifar10_%s.tfrecord'
SPLITS_TO_SIZES = {'train': 50000, 'test': 10000}
_NUM_CLASSES = 10
_ITEMS_TO_DESCRIPTIONS = {
'image': 'A [32 x 32 x 3] color image.',
'label': 'A single integer between 0 and 9',
}
def get_split(split_name, dataset_dir, file_pattern=None, reader=None):
"""Gets a dataset tuple with instructions for reading cifar10.
Args:
split_name: A train/test split name.
dataset_dir: The base directory of the dataset sources.
file_pattern: The file pattern to use when matching the dataset sources.
It is assumed that the pattern contains a '%s' string so that the split
name can be inserted.
reader: The TensorFlow reader type.
Returns:
A `Dataset` namedtuple.
Raises:
ValueError: if `split_name` is not a valid train/test split.
"""
if split_name not in SPLITS_TO_SIZES:
raise ValueError('split name %s was not recognized.' % split_name)
if not file_pattern:
file_pattern = _FILE_PATTERN
file_pattern = os.path.join(dataset_dir, file_pattern % split_name)
# Allowing None in the signature so that dataset_factory can use the default.
if not reader:
reader = tf.TFRecordReader
keys_to_features = {
'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
'image/format': tf.FixedLenFeature((), tf.string, default_value='png'),
'image/class/label': tf.FixedLenFeature(
[], tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
}
items_to_handlers = {
'image': slim.tfexample_decoder.Image(shape=[32, 32, 3]),
'label': slim.tfexample_decoder.Tensor('image/class/label'),
}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers)
labels_to_names = None
if has_labels(dataset_dir):
labels_to_names = read_label_file(dataset_dir)
return slim.dataset.Dataset(
data_sources=file_pattern,
reader=reader,
decoder=decoder,
num_samples=SPLITS_TO_SIZES[split_name],
items_to_descriptions=_ITEMS_TO_DESCRIPTIONS,
num_classes=_NUM_CLASSES,
labels_to_names=labels_to_names)
def has_labels(dataset_dir, filename='labels.txt'):
"""Specifies whether or not the dataset directory contains a label map file.
Args:
dataset_dir: The directory in which the labels file is found.
filename: The filename where the class names are written.
Returns:
`True` if the labels file exists and `False` otherwise.
"""
return tf.gfile.Exists(os.path.join(dataset_dir, filename))
def read_label_file(dataset_dir, filename='labels.txt'):
"""Reads the labels file and returns a mapping from ID to class name.
Args:
dataset_dir: The directory in which the labels file is found.
filename: The filename where the class names are written.
Returns:
A map from a label (integer) to class name.
"""
labels_filename = os.path.join(dataset_dir, filename)
with tf.gfile.Open(labels_filename, 'rb') as f:
lines = f.read().decode()
lines = lines.split('\n')
lines = filter(None, lines)
labels_to_class_names = {}
for line in lines:
index = line.index(':')
labels_to_class_names[int(line[:index])] = line[index + 1:]
return labels_to_class_names
读取的话就非常简单了:
dataset = cifar10.get_split('train', DATA_DIR)
provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
[image, label] = provider.get(['image', 'label'])
以上所有代码都可以在 tensorflow/model 仓库下的 slim 中找到~
总结
流程:
- 生成 TFRecord 格式文件
- 定义 record reader 分析 TFRecord 文件
- 定义 batcher
- 构建网络模型
- 初始化所有运算符
- 开始 queue runners.
- 训练 loop